Sampling
Sampling is used in some research projects and it is important to get this critical part of a research project done as well as possible. Some basic concepts of sampling will be covered here.
The collection of all the objects in the target group is called the population. With a small universe it is often possible to survey every member of the group. However we can seldom collect data from every member of a large universe. Still we can make some reliable statements about a large universe if we observe the characteristics of a carefully selected sub-group of that universe. It's like evaluating a whole pot of soup by sipping a spoonful after stirring the pot. The process of picking that sub-group is called sampling.
The steps in sampling are:
- Define the universe: What is your target study group?
- Identify the source of names: Is there a comprehensive list anywhere?
- Determine the size of the sub-group; how many of the total will you select?
- Pick the actual members: Which of those on the list will you observe?
If we want to know the opinion of the American public on an issue where do we get the names? The universe is all people in the USA but who has the list? Probably the researcher will have to accept a close substitute for the universal list, maybe the names in all the phone books in the USA or the list of everybody with Social Security numbers.
The size of the sub-group depends on the degree of accuracy you want in your results: the bigger the sample size, the more accurate your estimates will be; also the more expensive the study will be. The method of selecting the sample is also critical to the accuracy of your results. Below is a table which indicates how many respondents or observations would be needed to obtain the various error ranges given that 95 out of 100 samples will reflect the total population within that error range.
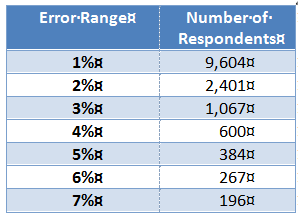
(This table is from Mildren Parten, Surveys, Polls, and Samples. Practical Procedures (New York: Harper, 1950), pp. 305-19. Quoted in James Engel, How Can I Get Them to Listen (Grand Rapids: Zondervan, 1980), p 55.)
The number of respondents needed (and therefore the cost of the survey) goes up exponentially as one pushes for a tighter error range. For this reason, you will seldom see survey results with an error range less than three percent. The method of selecting the actual members of a sample is a highly developed science but the basics are fairly simple. First the members have to come from the universe under study (they need to be representative) and second the members need to be chosen in such a way that every member has an equal likelihood of being selected. Picking the members at random accomplishes this.
There are several types of random sampling. Here are some examples:
- Simple random sampling Out of a universe of 300 members of Grace Foursquare Church pick a 10% sample. Write the name of each member on a piece of paper, put the pieces in a hat and pick thirty names out of the hat.
- n-th select or systematic random sample. Same situation as above but this time randomly pick a number between 1 and 10. Beginning at that number, pick every thirtieth name on the list.
- Stratified random sample. Divide the universe along some important category (age, gender, income, etc.). Then use simple or n-th select random sampling within each category.
- Area cluster sample. Get a map of the area to be surveyed. Divide the map using a grid. Select cells from the grid at random. Select individuals within the cells at random.
Sometimes it will simply be impossible to obtain a sample that is really random. And without the quality of randomness in the sample the researcher technically cannot make statements about the total population based on the sample. In the real world a second best course of action is possible. First, do your best to get a random sample. Then, try and discover any reason why there would be a bias in the sample. If there is no reason to believe that the sample is biased, then just assume it is random. If there is reason to believe that the sample is biased, use logic to figure out what kind of influence this bias might have on your sample.
Here is a simple exercise:
- A researcher is testing what percent of the population of a province is Christian. He selects, at random, a 3% sample of names from the provincial tax roll and finds that 10% claim to be Christian. Will the researcher be able to say with any degree of statistical confidence that this is the percent for the whole province? What biases may, exist?' if could- be that, the source of names may be a source of bias in the sample. What if the universe of registered taxpayers in that province has a different percentage of Christians that the rest of the total population? Is it likely to be a higher percent or a lower? What if taxpayers primarily live in the city and not the barrio and we know that, in general, urban populations have a higher Christian percentage than rural populations? What influence will that have on our estimate of the Christian percentage for the whole province?
See How Can I Get Them to Listen? by James Engel for a discussion of non-random sampling methods. The Survey Research Handbook by Alreck and Stettle has an excellent discussion of sampling error and bias and the implications.
attached files:
{kind=link}
- Log in to post comments